FinOps sin sustos
Publicado el
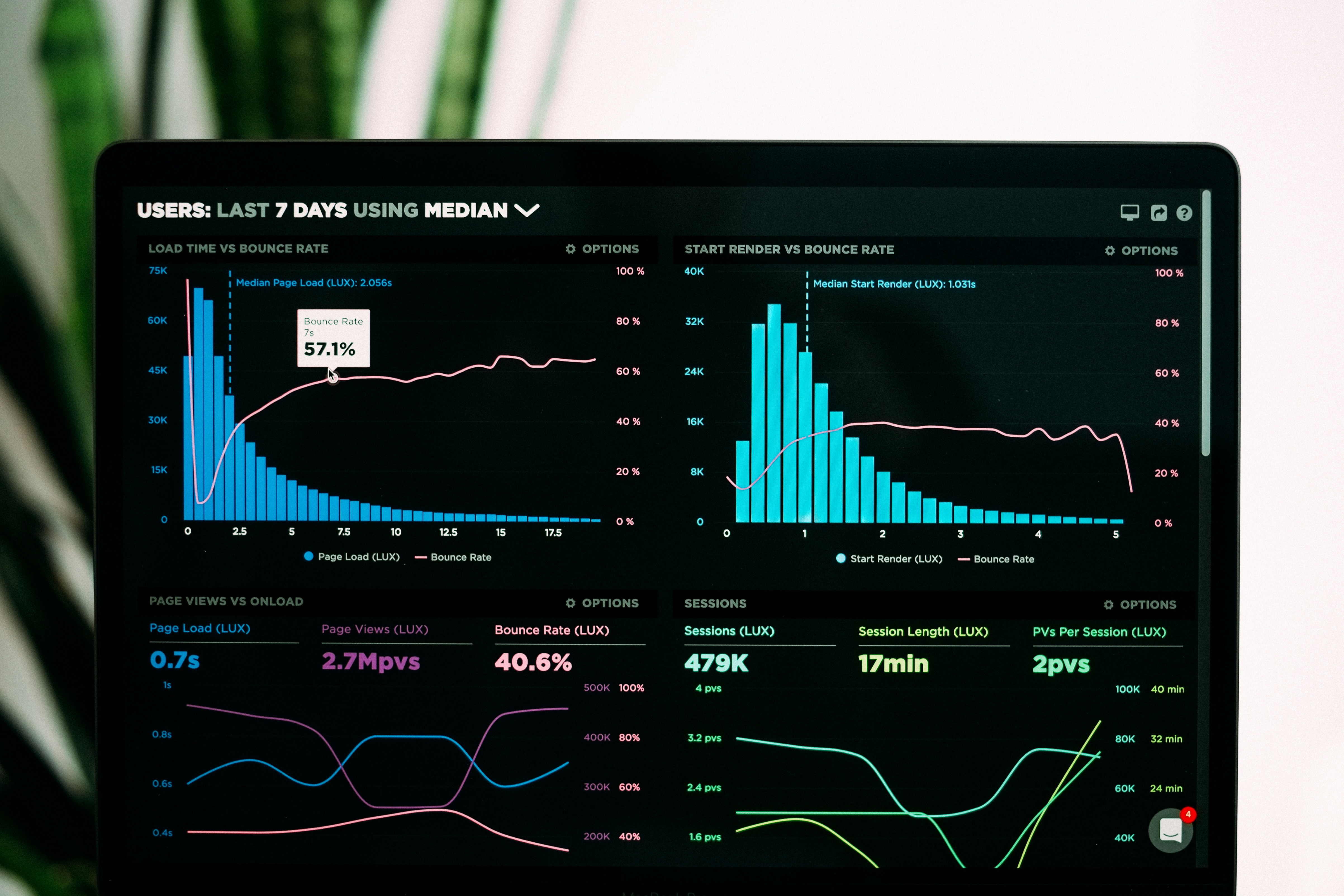
FinOps sin sustos: presupuestos, alertas y “kill switch” para tus proyectos en la nube
Seguro que te ha pasado (o te lo imaginas): vas a revisar una métrica, te despistas un fin de semana… y el lunes la factura “ha aprendido a multiplicarse”. En side-projects y pymes esto duele doble, porque normalmente no tienes un equipo dedicado mirando costes cada día.
La buena noticia es que no necesitas herramientas enterprise para dar un salto enorme de madurez. Con tres piezas bien planteadas puedes dormir mucho más tranquilo:
- Presupuestos por proyecto/entorno (para que el gasto tenga “dueño”).
- Alertas escalonadas (50/80/100%) con notificaciones que realmente llegan.
- Acciones automáticas realistas (un “kill switch” gradual, no una bomba nuclear).
Nota: en este artículo hablo de AWS/Azure/GCP porque son los tres “clásicos”, pero los principios valen igual si usas un BaaS o servicios gestionados. Si te interesa el enfoque de estimación y “cost drivers” antes de poner guardrails, te puede encajar BaaS y costes ocultos.
1. De la visibilidad a los guardrails: por qué el dashboard no basta
Un dashboard FinOps es como el velocímetro del coche: útil, pero no te salva si te quedas dormido. El salto de madurez llega cuando añades guardrails: límites, alertas y acciones que reducen el impacto de un error, incluso cuando nadie está mirando.
En la práctica, los guardrails responden a tres preguntas muy simples:
- ¿Cuánto puedo gastar al mes en este proyecto y en este entorno?
- ¿Cómo me entero a tiempo de que voy mal?
- ¿Qué pasa automáticamente si sigo gastando?
Si ya tienes visibilidad, perfecto. Si no, antes de automatizar conviene tener una base mínima (por ejemplo, un panel sencillo multi‑cloud). En ese caso, empieza por aquí: Dashboard FinOps DIY.
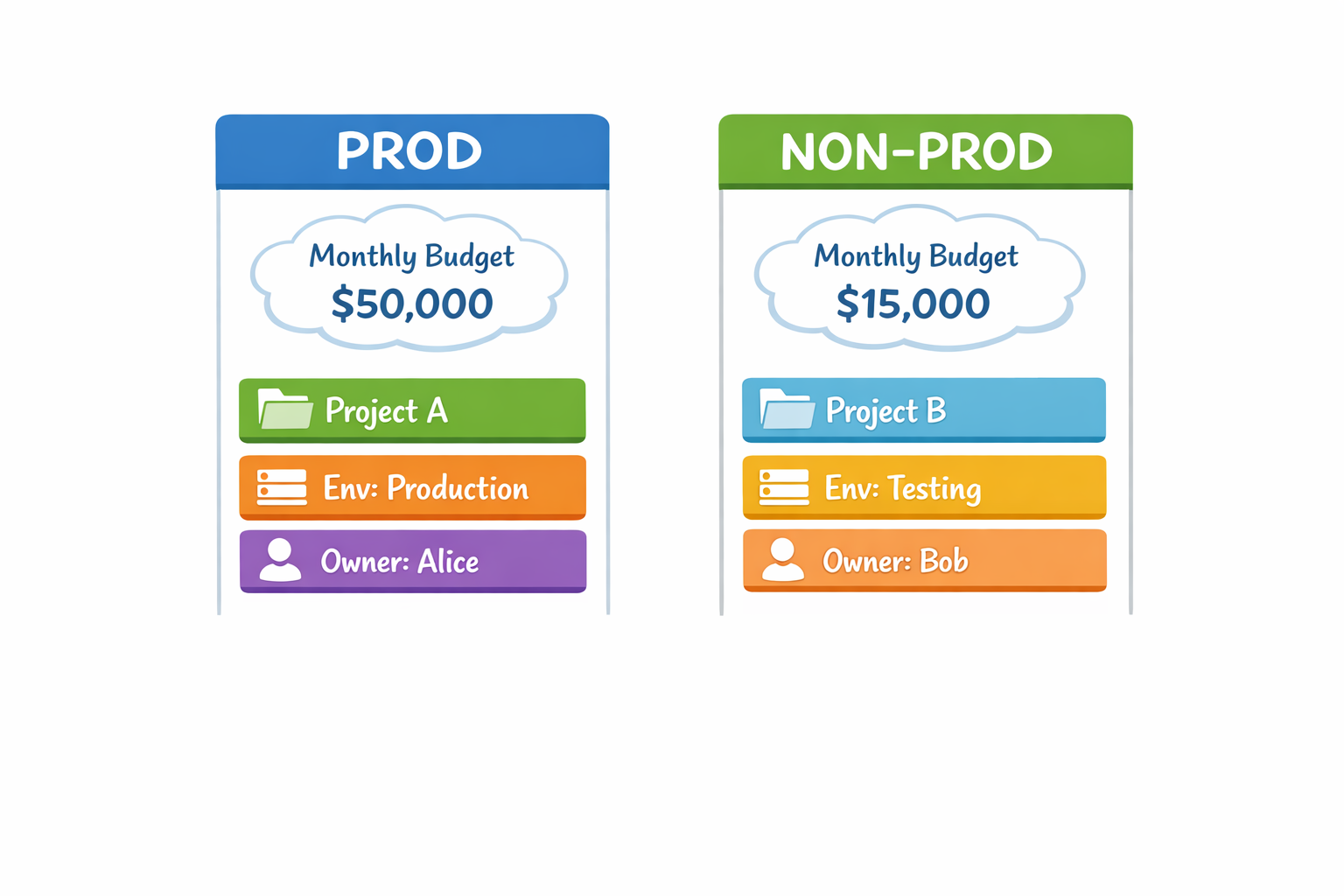
2. Presupuestos que sirven: proyecto, entorno y “cost drivers”
El error típico es poner un único presupuesto “global” de la cuenta. Eso no te dice qué se ha roto, ni te ayuda a actuar con precisión.
Para pymes y side-projects, un modelo práctico (y mantenible) es este:
- Presupuesto por proyecto (producto/cliente/servicio).
- Dentro del proyecto, separar al menos:
prod(lo que no quieres romper)non-prod(dev/staging/preview, donde puedes ser más agresivo)
2.1 Cómo “partir” el gasto por proyecto/entorno
Hay varias formas, de menos a más madura (elige la que te dé menos fricción):
- Etiquetas/labels/tags:
project,env,owner. - Contenedores por entorno: accounts, subscriptions, resource groups, projects.
- Cuentas separadas (cuando crece la complejidad): más aislamiento, más gestión.
En side-projects, tags + una convención clara suele ser el 80/20. En pymes, muchas veces compensa resource groups/subscriptions por entorno para aislar mejor.
2.2 Define el presupuesto con un margen “humano”
Un presupuesto útil no es el número exacto: es un límite que te ayuda a tomar decisiones sin drama.
- Si tu gasto normal es 30 €/mes, un presupuesto de 31 € es frágil.
- Uno de 60 € quizá no te protege de nada.
Una regla simple: presupuesto = gasto “normal” + margen de aprendizaje (p. ej., +20–40% al principio). Luego lo ajustas con datos reales.
3. Alertas 50/80/100% que realmente funcionan (y llegan a quien toca)
El objetivo de las alertas no es “spamearte”. Es darte tres momentos de decisión, cada uno con una acción asociada:
- 50%: “Todo normal, pero ya hay tendencia” (solo notificación).
- 80%: “Hora de mirar” (notificación + contención suave).
- 100%: “Stop” (kill switch: acciones automáticas + bloqueo de despliegues).
“Si te enteras por la factura, ya vas tarde. La alerta es el inicio; la acción automática es el seguro.”
3.1 AWS: presupuestos + notificación (base) + acción (si quieres)
En AWS lo habitual es:
- Definir el presupuesto (coste o uso) y filtrarlo por tags o por account.
- Enviar alertas a un canal (email, SNS, etc.).
Para pymes, una buena progresión es:
- Empieza con alertas por email bien configuradas (y que alguien lea).
- Añade un canal central (Slack/Teams) cuando ya te funcione el email.
- Si necesitas acciones, convierte la alerta en un evento que dispare automatización (por ejemplo, vía mensajería).
3.2 Azure: budgets + action groups
Azure suele encajar bien cuando ya usas Azure Monitor:
- Presupuesto en Cost Management.
- Alertas que disparan un Action Group (email, webhook, notificaciones a canales, etc.).
El punto clave es que la alerta no dependa de una persona concreta: debe llegar al “canal del proyecto”.
3.3 GCP: budgets + notificación y automatización
En Google Cloud puedes crear presupuestos y alertas asociados a un billing account y, a partir de ahí, integrarlos con notificaciones. La idea es la misma: convertir “me avisaron” en “pasó algo” (evento) para que tu sistema responda.
3.4 Notificaciones centralizadas: un solo sitio donde enterarte de todo
Da igual cuántos proveedores uses. Lo que quieres es un tablero mental único:
- Un canal de Slack/Teams/Discord por proyecto.
- Un email de equipo (no de una persona).
- Un “registro” simple (una hoja o un ticket automático) para trazabilidad.
Aquí es donde el no-code tiene sentido: te permite conectar alertas a Slack/Teams rápido, sin montar infraestructura. Pero hay un matiz importante: cuando el gasto está en rojo, tu automatización no puede fallar.
4. El “kill switch” sin drama: acciones automáticas realistas
Llamo “kill switch” a una estrategia de contención automática, pero gradual. En vez de “apagarlo todo”, defines niveles con impacto creciente.
Una forma muy operativa de plantearlo:
4.1 Nivel 1 (80%): contención suave, sin tocar producción
Acciones típicas con buen ratio beneficio/riesgo:
- Pausar entornos no críticos (staging/preview/dev).
- Detener recursos que no deberían estar 24/7 (máquinas, jobs de batch, entornos de pruebas).
- Reducir escalado automático en no‑prod (si tienes autoscaling).
- Limitar trabajos programados (por ejemplo, bajar frecuencia de un crawler o analytics batch).
4.2 Nivel 2 (100%): frenar crecimiento del coste
Aquí ya buscas “cortar la hemorragia”:
- Bloquear despliegues (para no empeorar).
- Rate limit en el borde (si tienes APIs públicas y un pico de tráfico te puede matar).
- Capar egress o poner límites de salida en servicios que lo permitan (muy relevante en picos por tráfico inesperado).
- Aplicar cuotas (cuando el proveedor lo soporte) a requests, jobs o throughput.
4.3 Nivel 3 (solo con plan): apagar a lo grande
Esto existe, pero úsalo con runbook y pruebas:
- Deshabilitar un proyecto/cuenta de forma temporal.
- Separar la facturación o cortar el “billing link” (medida extrema).
- Denegar permisos por IAM para detener creación de recursos.
5. Bloquea despliegues cuando el presupuesto está en rojo (CI/CD y hosting)
Una fuente frecuente de sustos es seguir desplegando cambios mientras el sistema está “en llamas”. Un guardrail muy rentable es un bloqueo de despliegues basado en el estado del presupuesto.
La idea técnica es simple:
- Tu alerta (o tu sistema de costes) actualiza un estado:
green/amber/red. - Tu pipeline (CI/CD) consulta ese estado antes de desplegar.
- Si está en
red, falla el paso y no se publica nada nuevo.
Esto es compatible con GitHub Actions, GitLab CI, Azure DevOps… y también con plataformas como Netlify: lo importante es el patrón, no el proveedor.
Estructura mínima para un “FinOps guardrails” (repo pequeño)
No es una plantilla rígida: es una forma de mantener presupuestos, notificaciones y runbooks en un sitio auditable.
/finops-guardrails
- runbooks/ (qué hacer en 50/80/100%)
- budgets/ (presupuestos por proyecto/entorno)
- notifications/ (canales, webhooks, mapping de proyectos)
- kill-switch/ (acciones por nivel: stop non-prod, rate limits, quotas)
- ci/ (check de “budget status” antes de deploy)
- README.md
6. Una hoja de ruta realista (en 1 tarde) para pymes y side-projects
Si intentas hacerlo todo de golpe, lo más probable es que lo abandones. Mejor en capas:
6.1 Capa 1: presupuesto + alertas por email (hoy mismo)
- Presupuesto mensual por proyecto (y si puedes, por entorno).
- Alertas 50/80/100% a un email compartido (o un grupo).
- Un “responsable” rotatorio: revisar a los 80% en menos de 24h.
6.2 Capa 2: canal central y registro mínimo (esta semana)
- Slack/Teams/Discord por proyecto.
- Un registro de incidentes de coste (puede ser un doc o una issue).
- Una mini‑revisión mensual: “qué cambió, qué aprendimos, qué ajustamos”.
6.3 Capa 3: kill switch gradual + bloqueo de despliegues (cuando ya funciona)
- Automatiza nivel 1 (no‑prod) y el bloqueo de despliegues.
- Añade nivel 2 solo si de verdad te aporta.
- Documenta el runbook y prueba la vuelta atrás.
7. No-code vs profesional: dónde está el equilibrio
El no‑code es útil cuando:
- Quieres conectar alertas a Slack/Teams en minutos.
- Estás validando un producto y no quieres montar nada “serio” todavía.
- Te sirve una automatización sencilla y el riesgo es bajo.
Pero hay tres razones por las que, llegado un punto, compensa hacerlo “bien” con un profesional:
- Fiabilidad: el día que te salva dinero, no puede fallar por un token caducado o un webhook mal configurado.
- Seguridad: automatizar acciones en cloud implica permisos; hay que diseñarlos con mínimo privilegio.
- Mantenibilidad: budgets, alertas y kill switch son “producto interno”. Si no se entiende, nadie lo mantiene.
En otras palabras: no se trata de demonizar el no‑code. Se trata de usarlo como rampa de acceso, y profesionalizarlo cuando tu proyecto ya justifica la inversión.
Checklist operativa (para que funcione sin vigilancia constante)
- Tengo presupuesto por proyecto y, como mínimo, separado en
prodynon-prod. - Tengo alertas 50/80/100% y llegan a un canal/equipo, no a una persona.
- Sé qué acción hago en 80% (runbook corto, sin “pensar”).
- Tengo un kill switch gradual probado (al menos para non‑prod).
- Mi CI/CD bloquea despliegues si el estado está en rojo.
- Reviso 1 vez al mes: presupuesto, umbrales y “cost drivers” principales.
Cierre: visibilidad + guardrails = dormir mejor (y gastar menos)
La visibilidad te ayuda a entender el gasto. Pero los guardrails te protegen cuando te equivocas, cuando hay un pico de tráfico o cuando un despliegue dispara consumo sin avisar.
Si quieres, puedo ayudarte a aterrizar esto en tu caso real (proveedor, arquitectura, riesgos y nivel de automatización), y dejarlo probado, documentado y mantenible. Si te encaja, escríbeme y lo planteamos paso a paso.