Infraestructura como código sin drama
Publicado el

Infraestructura como código sin drama: baseline dev/staging/prod con Terraform + Gu00F3digoitHub Actions
Si ya tienes un proyecto en la nube en marcha, es muy probable que te suene esta escena: necesitas un staging “igual que prod”, alguien entra al panel, replica “más o menos” lo que recuerda… y a las dos semanas nadie entiende por qué ese entorno se comporta distinto (o por qué cuesta el doble).
El problema no suele ser la nube. El problema es el click-ops: infraestructura creada “a mano”, sin historia, sin revisiones y con diferencias invisibles entre entornos.
En este artículo te propongo un enfoque 80/20 para pymes y side-projects: construir un baseline reproducible (dev/staging/prod) con Terraform, versionarlo en Git y automatizarlo con GitHub Actions para que sea auditable, repetible y mantenible.
Lo que te llevas al terminar:
- Qué es exactamente un baseline y por qué es el punto de partida correcto (antes de “hacer IaC de todo”).
- Qué merece IaC en pequeño (y qué no, todavía) para evitar el drama.
- Una estructura de repositorio y state pensada para dev/staging/prod.
- Un flujo de PRs con
planautomático y unapplycontrolado. - Checklist final + errores típicos (state, drift, permisos, rotación de secretos).
1. Qué es un “baseline” y por qué te ahorra problemas (aunque tu proyecto sea pequeño)
Piensa en un baseline como la plataforma mínima sobre la que tu aplicación vive sin sorpresas:
- Identidad y permisos (IAM) para que cada cosa tenga el mínimo acceso posible.
- Secretos y configuración, separados por entorno.
- DNS y certificados/TLS (o su equivalente en tu stack).
- Storage básico (assets, backups, logs, artefactos).
- Convenciones: nombres, etiquetas, límites, variables… y quién puede tocar qué.
En un equipo grande esto es “plataforma”. En una pyme, suele ser “lo que alguien configuró una tarde”. En ambos casos, si no está versionado y revisado, termina en:
- Entornos con diferencias accidentales (lo peor, porque no se ven).
- Pérdida de tiempo en “reconstruir” lo que ya existía.
- Riesgo operativo: permisos excesivos, secretos en sitios incorrectos, cambios sin trazabilidad.
- Riesgo de coste: recursos huérfanos o mal dimensionados que nadie se atreve a tocar.
Si ya estás trabajando FinOps y guardrails, el baseline es el siguiente salto lógico: haces reproducible lo que proteges. Si quieres contexto sobre guardrails y control de costes, te puede encajar leer antes: FinOps sin sustos: presupuestos, alertas y “kill switch”.
2. Qué merece IaC en pequeño (y qué no) — enfoque 80/20
El error típico es intentar modelar el 100% de la nube en Terraform desde el día 1. Para un proyecto pequeño, eso suele acabar en frustración. El enfoque que mejor funciona es este: empieza por lo estable y repetible.
| Área | Sí merece IaC (baseline) | Mejor dejarlo para después |
|---|---|---|
| DNS | Zonas/records críticos, subdominios por entorno | Experimentos temporales, registros “de prueba” |
| IAM | Roles de CI, permisos mínimos, separación por entorno | Políticas ultra-finas si aún no tienes claridad |
| Secretos | Dónde viven, quién accede, rotación mínima | Automatización avanzada de rotación si no la necesitas |
| Storage | Buckets básicos (assets/backups/logs) + reglas | Lifecycle complejo si no tienes volumen |
| Observabilidad | Un mínimo de logs/métricas y alertas | Un APM completo si aún estás validando producto |
| Red | Lo imprescindible (seguridad por defecto) | Arquitecturas complejas (VPC/peering) sin demanda real |
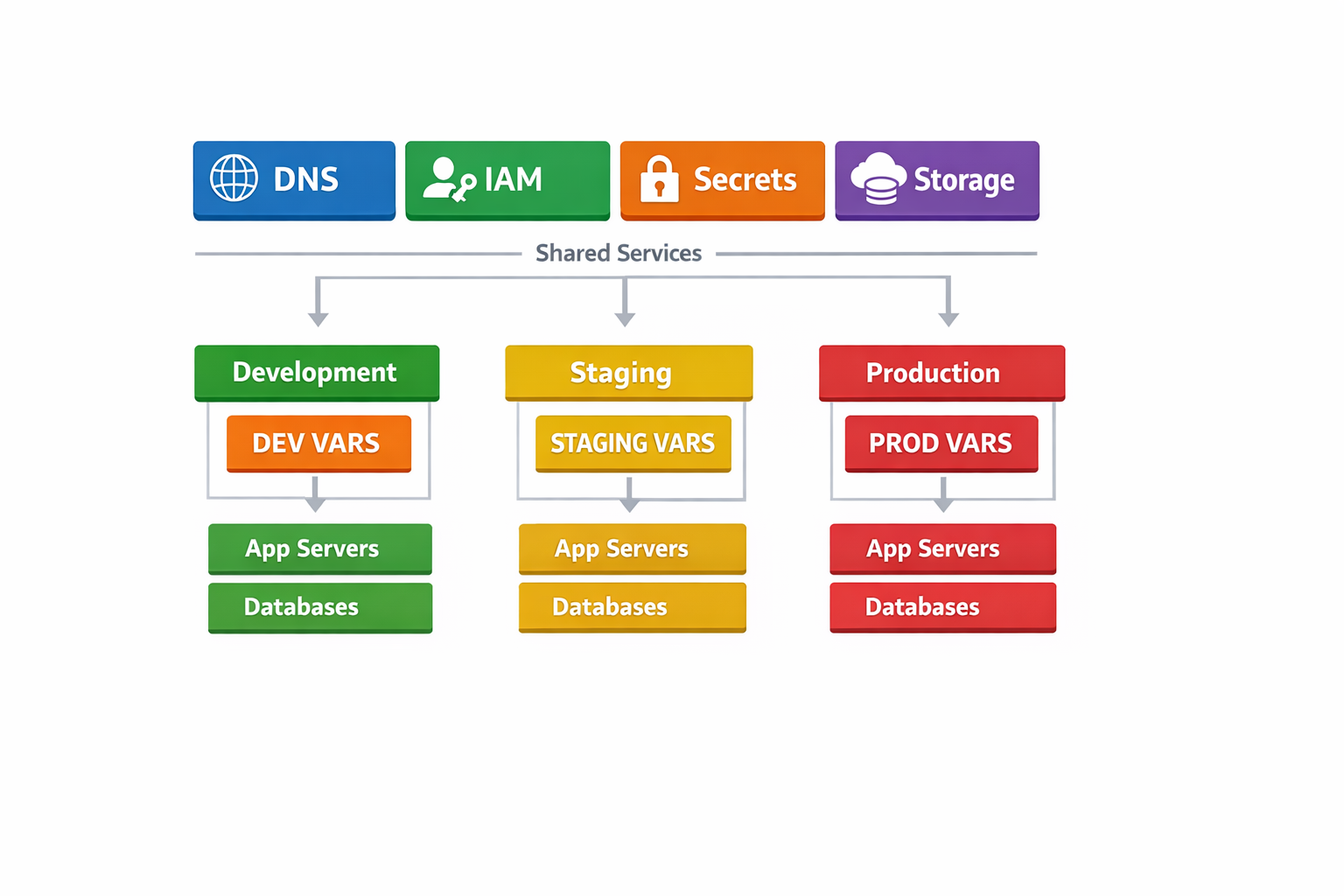
La idea es muy simple: el baseline debe ser fácil de explicar en 5 minutos. Si no, todavía no es baseline: es un proyecto en sí mismo.
3. Repo y state sin drama: estructura mínima para dev/staging/prod
Aquí es donde se ganan (o se pierden) muchas horas. Dos decisiones te evitan la mayoría de problemas:
- Un state remoto por entorno (y con bloqueo/locking).
- Variables por entorno en ficheros
*.tfvars(sin secretos dentro).
3.1 Estructura 80/20 del repositorio
Una estructura típica y mantenible para un baseline pequeño:
Estructura 80/20 para un baseline IaC
No es una plantilla rígida: es un punto de partida para crecer sin perder trazabilidad.
/infra
- README.md
modules/
- dns/
- iam/
- secrets/
- storage/
envs/
- dev/
- staging/
- prod/
.github/
workflows/
- terraform-plan.yml
- terraform-apply.yml
- terraform-drift.yml
- scripts/
modules/: piezas reutilizables (DNS, IAM, secretos, storage). Mantén módulos pequeños y sin magia.envs/dev|staging|prod: cada entorno compone módulos + variables..github/workflows: automatización deplan,applyy detección de drift.scripts/: utilidades (por ejemplo, validar naming o generar documentación simple).
3.2 Cómo separar entornos sin duplicar todo
En envs/prod no quieres “otro Terraform distinto”. Quieres el mismo baseline con variables (y, si hace falta, algún toggle controlado).
Ejemplo conceptual (simplificado) dentro de envs/staging/main.tf:
module "dns" {
source = "../../modules/dns"
project = var.project
env = var.env
}
module "storage" {
source = "../../modules/storage"
project = var.project
env = var.env
}Y variables por entorno en envs/staging/staging.tfvars:
project = "mi-producto"
env = "staging"
# region, nombres, tamaños, límites... (sin secretos)Clave operativa: los secretos no deberían vivir en *.tfvars si ese fichero termina en el repo. En su lugar, usa un gestor de secretos y/o secretos cifrados en el sistema de CI.
3.3 El state: la pieza que nadie ve (y que más problemas da)
Terraform guarda el estado real de tu infraestructura en un fichero llamado state. Si no lo tratas bien, aparecen estos dramas clásicos:
- Dos personas aplican cambios a la vez (sin locking) y el state se corrompe.
- Se pierde el state y “Terraform ya no sabe qué existe”.
- El state contiene datos sensibles (por ejemplo, IDs o outputs) y termina expuesto.
Recomendación práctica para pymes:
- Usa state remoto con bloqueo y cifrado.
- Separa el state por entorno:
dev,staging,prod. - Restricción de acceso: solo CI y cuentas/roles específicos.
Ejemplo conceptual de backend remoto (sin casarte con un proveedor):
terraform {
backend "remote" {
# Puede ser un backend gestionado o un storage remoto con locking.
# Lo importante es: remoto, cifrado y con bloqueo.
}
}Si tu proyecto ya usa CI/CD con GitHub Actions (como en tus pipelines de Astro y Netlify), este patrón encaja especialmente bien: revisas cambios en PR y aplicas con control. Si te interesa el enfoque de pipeline “paso a paso”, aquí tienes una guía relacionada: CI/CD para Astro y Netlify con GitHub Actions.
4. Terraform + GitHub Actions: PR con plan, merge con apply (controlado)
El objetivo no es “hacer deploy automático de infraestructura”. El objetivo es que cada cambio sea:
- Revisable (plan visible en el PR).
- Aplicable con seguridad (apply controlado).
- Trazable (quién, cuándo y por qué).
4.1 Flujo recomendado (sin complicarte)
- Pull Request:
terraform fmt -checkterraform init+terraform validateterraform plany publicación del resumen en el PR
- Merge a main:
terraform applysolo si:- El PR ha sido aprobado
- Estás en el entorno correcto
- El workflow tiene permisos mínimos y autenticación segura
- Programado (opcional):
terraform plannocturno para detectar drift
4.2 Seguridad: evita llaves largas, usa identidad (OIDC) cuando puedas
En CI/CD, el error típico es meter credenciales “de por vida” en secrets. Funciona… hasta que alguien las filtra o se van heredando sin control.
Un enfoque más robusto es usar autenticación basada en identidad (por ejemplo, OIDC) para que GitHub Actions obtenga un token temporal y asuma un rol con permisos limitados. A nivel conceptual:
- En
plan: permisos de lectura (o lo mínimo imprescindible). - En
apply: permisos de escritura, pero solo en el entorno correcto y con protección.
4.3 Workflow de ejemplo (conceptual) para plan en PR
Este YAML es intencionalmente simple: muestra el patrón, no una receta cerrada.
name: terraform-plan
on:
pull_request:
paths:
- "infra/**"
permissions:
contents: read
pull-requests: write
id-token: write
jobs:
plan:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: hashicorp/setup-terraform@v3
- name: Terraform fmt
working-directory: infra/envs/staging
run: terraform fmt -check -recursive
- name: Terraform init
working-directory: infra/envs/staging
run: terraform init -input=false
- name: Terraform validate
working-directory: infra/envs/staging
run: terraform validate
- name: Terraform plan
working-directory: infra/envs/staging
run: terraform plan -input=false -no-colorNotas rápidas:
- En un baseline con varios entornos, puedes ejecutar planes por matriz (
dev,staging) y dejarprodpara un flujo más controlado. - Si publicas el plan como comentario, evita volcar información sensible. A veces basta con un resumen de recursos cambiados.
4.4 apply controlado: “automático” no significa “sin control”
Para pymes y side-projects, suele funcionar muy bien este patrón:
applysolo enmain- Asociado a un GitHub Environment (por ejemplo,
prod) con:- required reviewers (aprobación manual)
- secrets/vars específicos del entorno
- Sin acceso de escritura a
proden PRs
En la práctica, te permite esta conversación interna:
- “Vemos el plan en el PR.”
- “Aprobamos el cambio.”
- “Aplicamos en prod con una puerta de seguridad.”
5. Drift, permisos y secretos: los errores típicos (y cómo evitarlos)
La IaC se rompe menos por Terraform y más por hábitos. Estos son los puntos donde conviene ser estricto desde el principio.
5.1 State: locking, backup y acceso mínimo
- Remote state con locking (sí o sí).
- Acceso limitado: CI y roles concretos.
- Backups (y prueba de restauración).
5.2 Drift: alguien cambia algo en el panel
Aunque hagas IaC, el “click-ops” puede volver… porque alguien tiene prisa.
Cómo detectarlo sin obsesionarte:
- Un workflow programado (
terraform plan) que avise si hay cambios inesperados. - Una regla cultural: “si existe en Terraform, se cambia en Terraform”.
5.3 Permisos: el “admin” permanente es deuda técnica
- Define permisos mínimos por flujo (plan vs apply).
- Aísla prod (y reduce quién puede tocarlo).
- Documenta el “por qué” de cada permiso crítico.
5.4 Secretos: rotación y fugas silenciosas
- No guardes secretos en
tfvars, ni en outputs que acabes imprimiendo en logs. - Ten un lugar único para secretos por entorno.
- Define una rotación mínima (aunque sea manual y trimestral).
6. Checklist operativa: que funcione sin vigilancia constante
Usa esta lista como “Definition of Done” del baseline:
- Hay dev/staging/prod con convención clara (nombres, etiquetas, variables).
- Cada entorno tiene state remoto independiente, con locking.
- El repositorio tiene módulos pequeños (DNS/IAM/secrets/storage) y documentación mínima.
- En PR se ejecuta
fmt,validateyplan(al menos para dev/staging). - En
mainexisteapplycontrolado (con protección paraprod). - CI usa identidad/tokens temporales cuando es posible; no llaves eternas.
- Los secretos viven fuera del repo y están separados por entorno.
- Hay un mecanismo de detección de drift (aunque sea semanal).
- Hay un runbook simple: “qué hacer si falla init/plan/apply”.
- Hay una revisión periódica (mensual o trimestral) de permisos y secretos.
Si además estás eligiendo nube o revisando arquitectura, te puede aportar contexto este artículo: Cómo elegir la plataforma de cloud computing adecuada.
Cierre: IaC no es complejidad, es repetición bien empaquetada
La infraestructura como código no va de convertirte en “SRE” de la noche a la mañana. Va de algo mucho más pragmático: dejar de repetir a mano lo que siempre repites, y poder demostrar (con un PR) qué cambia, por qué y cuándo.
Si quieres, puedo ayudarte a diseñar este baseline para tu caso real (stack, nube, tamaño del equipo, necesidades de coste/seguridad) y dejarlo funcionando con un flujo de PRs que no dé pereza mantener. Escríbeme y lo aterrizamos paso a paso.