Paginación con cursor (keyset): adiós a page=N y a los duplicados
Publicado el

Paginación con cursor (keyset): adiós a page=N y a los duplicados
Seguro que te ha pasado: abres un listado (pedidos, leads, tickets…), bajas un poco, pulsas “Siguiente” o “Cargar más”… y de repente aparecen elementos repetidos, otros “desaparecen”, o la carga de la página 50 tarda una eternidad.
No es tu imaginación. En listados grandes (y especialmente en datasets que cambian mientras navegas) la paginación por offset (page=N, OFFSET) empieza a fallar por diseño.
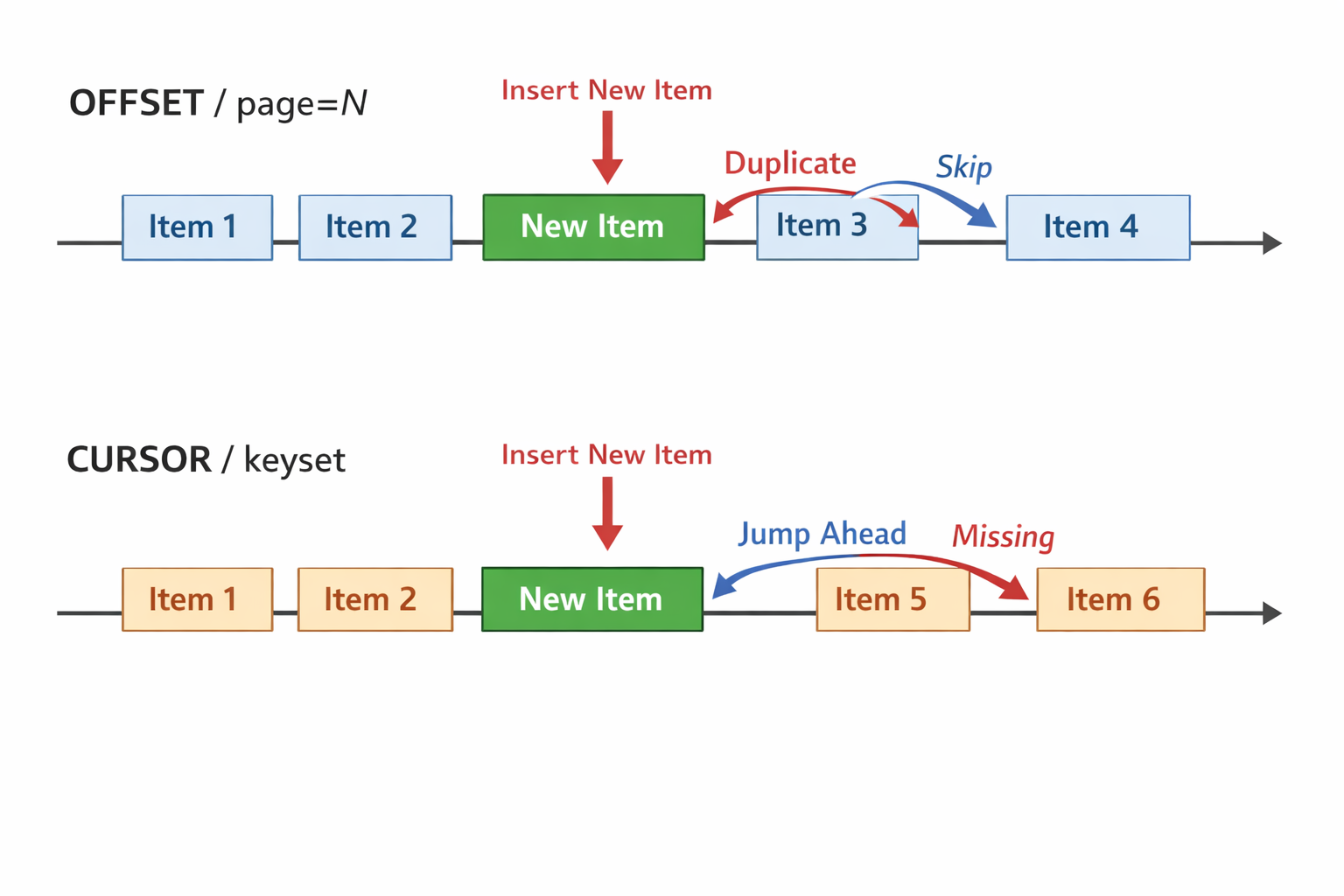
1. El problema de page=N: cuando el offset deja de ser tu amigo
La paginación por offset suele verse así:
- API:
GET /api/items?page=4&pageSize=20(ooffset=60&limit=20) - SQL:
ORDER BY ... LIMIT 20 OFFSET 60
Es fácil de entender… hasta que el listado crece o el dataset está “vivo”.
1.1. Rendimiento: cuanto más lejos, más caro
En un offset grande, la base de datos tiene que saltar una cantidad creciente de filas para llegar a “tu página”. Aunque haya índices, ese “saltar N filas” no suele ser gratis: el coste y la latencia tienden a empeorar conforme aumentas page.
Se traduce en lo típico:
- Página 1 vuela.
- Página 20 va “bien”.
- Página 200 empieza a doler.
- Página 2000 se convierte en un incidente.
1.2. Consistencia: duplicados y saltos cuando el dataset cambia
El fallo más frustrante no es la lentitud; es que el usuario ve cosas raras:
- Elementos duplicados al pasar de una página a otra.
- Elementos que “se pierden” (nunca llegan a mostrarse).
- Orden que parece cambiar sin motivo.
¿Por qué? Porque el offset depende del número de filas anteriores. Si entre la petición de la página 1 y la de la página 2 entran registros nuevos, o cambian algunos, el “desplazamiento” ya no apunta a lo mismo.
Ejemplo típico en un feed ordenado por fecha:
- Pides
page=1(20 registros más recientes). - Entra un registro nuevo.
- Pides
page=2conOFFSET 20. - El registro nuevo ha “empujado” el listado y tu
OFFSET 20ya no empieza exactamente donde creías.
Resultado: duplicados o huecos.
2. Qué es la paginación por cursor (keyset), explicado sin jerga
La alternativa es dejar de decir “dame la página 4” y empezar a decir:
“Dame los siguientes 20 elementos a partir del último que ya te pedí.”
Eso es paginación por cursor. En vez de page=N, la API devuelve un token (cursor) que representa tu posición actual. Tú se lo devuelves en la siguiente llamada.
“Una paginación robusta no es un ‘detalle de backend’: es parte del contrato entre tu API y la experiencia de tu producto.”
En la práctica:
- La primera respuesta devuelve
items+nextCursor. - La siguiente petición envía
cursor=...y recibe la siguiente tanda.
El cursor suele basarse en un criterio de orden estable (por ejemplo createdAt y un id como desempate).
3. La receta mínima para que funcione (sin trucos raros)
La paginación keyset es sencilla, pero exige disciplina. Si te saltas estos puntos, vuelves a los mismos problemas con otro nombre.
3.1. Define un orden estable (y repítelo en todas partes)
Un “orden estable” significa:
- Todos los registros tienen una posición única en el orden.
- Esa posición no cambia porque otros registros se inserten o se borren.
La receta típica es:
- Campo principal:
created_at(oupdated_at, oid) - Desempate:
id
Por ejemplo, orden descendente (lo más nuevo primero):
ORDER BY created_at DESC, id DESC
3.2. Cursor compuesto: createdAt + id
Si ordenas solo por created_at, dos filas pueden compartir el mismo valor. Ahí nacen los duplicados “fantasma”.
Con cursor compuesto, tu cursor guarda ambos valores:
{ "createdAt": "2025-12-29T10:15:00.000Z", "id": "a1b2c3" }Y en la query pides “todo lo que va después de ese punto del orden”.
3.3. Haz el cursor opaco (para no acoplarte)
El cliente no debería “entender” el cursor. Debe tratarlo como un token:
- Puedes codificarlo como Base64URL de un JSON.
- Si te preocupa manipulación, puedes firmarlo (HMAC) o cifrarlo.
- Mantén el contrato estable:
cursorentra,nextCursorsale.
4. SQL de referencia: OFFSET vs keyset (con cursor compuesto)
Para aterrizarlo, imagina una tabla orders con:
id(único)created_at(fecha de creación)- otros campos…
4.1. La versión por offset
SELECT id, created_at, total
FROM orders
ORDER BY created_at DESC, id DESC
LIMIT 20
OFFSET 4000;Funciona… hasta que tu offset crece o el dataset se mueve.
4.2. La versión keyset: “a partir del último elemento”
Primera página (sin cursor):
SELECT id, created_at, total
FROM orders
ORDER BY created_at DESC, id DESC
LIMIT 20;Siguientes páginas (con cursor (:createdAt, :id) del último item de la página anterior):
SELECT id, created_at, total
FROM orders
WHERE (created_at < :createdAt)
OR (created_at = :createdAt AND id < :id)
ORDER BY created_at DESC, id DESC
LIMIT 20;Si tu base de datos soporta comparación de tuplas, puedes expresarlo como:
SELECT id, created_at, total
FROM orders
WHERE (created_at, id) < (:createdAt, :id)
ORDER BY created_at DESC, id DESC
LIMIT 20;La idea es siempre la misma: en vez de “saltar” filas, le dices al motor “empieza desde aquí”.
5. Endpoint en TypeScript: items + nextCursor (listo para “Cargar más”)
Aquí tienes un ejemplo genérico en TypeScript (aplicable como API route, serverless function o backend clásico). El patrón clave es:
- Pides
limit + 1para saber si hay “siguiente página”. - Si hay más, recortas a
limity generasnextCursorcon el último elemento.
type Cursor = { createdAt: string; id: string };
function encodeCursor(cursor: Cursor): string {
return Buffer.from(JSON.stringify(cursor), "utf8").toString("base64url");
}
function decodeCursor(raw: string): Cursor | null {
try {
const json = Buffer.from(raw, "base64url").toString("utf8");
const parsed = JSON.parse(json) as Partial<Cursor>;
if (!parsed.createdAt || !parsed.id) return null;
return { createdAt: parsed.createdAt, id: parsed.id };
} catch {
return null;
}
}
function clamp(n: number, min: number, max: number) {
return Math.max(min, Math.min(max, n));
}
// Pseudocódigo de acceso a datos: reemplázalo por tu ORM/driver.
async function queryOrders(sql: string, params: unknown[]) {
// return db.query(sql, params);
throw new Error("TODO: implementa tu acceso a base de datos");
}
export async function listOrders(input: { cursor?: string | null; limit?: number }) {
const limit = clamp(Number(input.limit ?? 20), 1, 50);
const cursor = input.cursor ? decodeCursor(input.cursor) : null;
const sqlFirstPage = `
SELECT id, created_at
FROM orders
ORDER BY created_at DESC, id DESC
LIMIT $1;
`;
const sqlNextPage = `
SELECT id, created_at
FROM orders
WHERE (created_at < $1) OR (created_at = $1 AND id < $2)
ORDER BY created_at DESC, id DESC
LIMIT $3;
`;
const rows = cursor
? await queryOrders(sqlNextPage, [cursor.createdAt, cursor.id, limit + 1])
: await queryOrders(sqlFirstPage, [limit + 1]);
const items = rows.slice(0, limit);
const hasMore = rows.length > limit;
const nextCursor = hasMore
? encodeCursor({
createdAt: items[items.length - 1].created_at,
id: items[items.length - 1].id,
})
: null;
return { items, nextCursor };
}Si quieres integrarlo en Astro + Netlify, lo habitual es envolver esta función en una API route (
src/pages/api/...) o en una Netlify Function. Si necesitas ese “pegamento”, te puede venir bien esta guía: Netlify Functions y Edge Functions con Astro.
6. Consumirlo desde Astro: “Cargar más” e infinite scroll (sin UX rota)
Una vez tu API devuelve nextCursor, el frontend se simplifica bastante: solo tienes que guardar ese token y pedir la siguiente tanda.
6.1. Patrón “Cargar más” (recomendado como base)
El botón es el punto medio perfecto:
- Más accesible (control explícito del usuario).
- Más fácil de depurar.
- Evita scroll infinito “sin fin” si no lo necesitas.
Ejemplo simplificado (vanilla JS, sin frameworks):
<div id="list"></div>
<button id="load-more" type="button">
Cargar más
</button>
<p id="status" aria-live="polite"></p>const list = document.getElementById("list");
const button = document.getElementById("load-more");
const status = document.getElementById("status");
let nextCursor = null;
let loading = false;
async function loadMore() {
if (loading) return;
loading = true;
button.disabled = true;
status.textContent = "Cargando…";
try {
const url = new URL("/api/orders", window.location.origin);
if (nextCursor) url.searchParams.set("cursor", nextCursor);
const res = await fetch(url);
if (!res.ok) throw new Error("Respuesta no válida");
const data = await res.json();
for (const item of data.items) {
const row = document.createElement("div");
row.textContent = `${item.id} — ${item.created_at}`;
list.appendChild(row);
}
nextCursor = data.nextCursor ?? null;
status.textContent = nextCursor ? "" : "No hay más resultados.";
button.disabled = !nextCursor;
button.textContent = nextCursor ? "Cargar más" : "Fin";
} catch {
status.textContent = "No se ha podido cargar más. Reintenta.";
button.disabled = false;
} finally {
loading = false;
}
}
button.addEventListener("click", loadMore);
loadMore(); // primera carga6.2. Infinite scroll: útil, pero con condiciones
El infinite scroll es cómodo, pero exige más cuidado (accesibilidad, SEO, foco, footer…). Si quieres comparar bien los patrones y ver implementaciones más completas, aquí tienes una guía específica: Paginación vs infinite scroll en Astro.
7. Cuándo NO usar cursor (y alternativas no-code “sin auto-sabotaje”)
La paginación por cursor es excelente para feeds y listados grandes, pero no es la respuesta a todo.
7.1. No lo uses si necesitas “ir a la página 50”
Keyset está pensado para navegar hacia delante (y, con más trabajo, hacia atrás). No es ideal cuando el requisito es:
- Saltar a un número de página concreto.
- Ir al final del listado “directamente”.
- Mostrar un contador exacto y barato del total (a veces se puede, pero no siempre conviene).
En esos casos, opciones razonables son:
- Offset tradicional si el dataset es pequeño o estable.
- Paginación clásica server-side (URLs por página) si el SEO del listado es crítico.
- Un enfoque híbrido: cursor para navegación y un “buscador/filtro” para saltos.
7.2. No-code: perfecto para validar, peligroso para escalar sin control
Si estás validando un producto o montando un backoffice interno, el no-code puede ser un acelerador real:
- Te da UI, filtros y paginación sin construir un backend.
- Puedes enseñar algo funcionando en días, no en semanas.
Pero hay un punto a partir del cual el “ahorro” sale caro:
- Cuando la performance importa (listados masivos, usuarios concurrentes).
- Cuando necesitas control de índices, permisos, auditoría, caching, observabilidad.
- Cuando la paginación deja de ser “pintar una tabla” y se vuelve contrato de API.
Ahí es donde compensa que un profesional te diseñe la solución con criterio (modelo de datos, orden estable, índices, límites, seguridad). Suele ser un poco más caro al principio, pero evita refactors y problemas justo cuando el producto empieza a crecer.
8. Estructura típica (Astro + API + UI) para no perderte
Estructura mínima para listados con cursor en Astro
Da igual si el endpoint vive como API route o como Function: lo importante es separar datos, endpoint y UI.
/
- src/
- pages/
- listado.astro
- api/
- orders.json.ts
- lib/
- pagination/
- cursor.ts
- netlify/
- functions/ (opcional)
- netlify.toml (opcional)
9. Cierre: una paginación “bien hecha” se nota… y una mal hecha también
Cuando el catálogo crece o el negocio empieza a moverse rápido, la paginación deja de ser un “detalle técnico”. Es parte de tu producto:
- Afecta a la percepción de calidad.
- Afecta a tiempos de carga (y a conversiones).
- Afecta a incidencias y a soporte (“no encuentro X”, “se duplica Y”).
Si quieres, puedo ayudarte a aterrizar esto en tu caso concreto: definir el orden estable, diseñar el cursor, optimizar índices y dejar una implementación lista (API + UI en Astro, con buen UX). Escríbeme y lo vemos paso a paso.